파이썬을 이용해서 글자를 인식하는 프로그램이다.
아래 블로거님을 참고해서 제작 했다.
(참고 링크)
Python에서 Tesseract 사용하기 for OCR
Tesseract 이미지로부터 텍스트를 인식하고, 추출하는 소프트웨어를 일반적으로 OCR이라고 한다. Tesseract는 1984~1994년에 HP 연구소에서 개발된 오픈 소스 OCR 엔진이며, 현재까지도 LSTM과 같은 딥러닝
junyoung-jamong.github.io
글자 인식을 위해서는 별도의 tesseract 프로그램이 필요하다. 설치방법은 위에 블로그를 참고 바란다.
아래 아이콘같은 파일이 다운로드 된다.
1. tesseract 설치하기

기본적으로 영어만 인식하게 되어있으며, 다른언어를 인식하게 끔 하려면 옵션선택을 해야 한다.
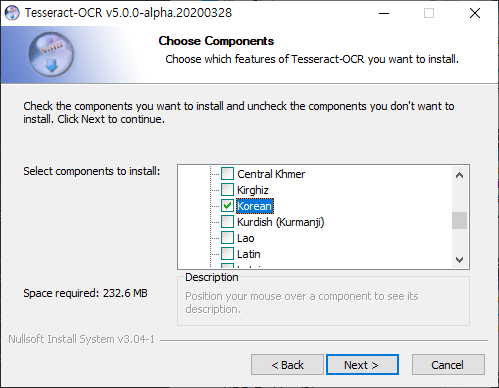
2. tesseract 환경변수 등록하기
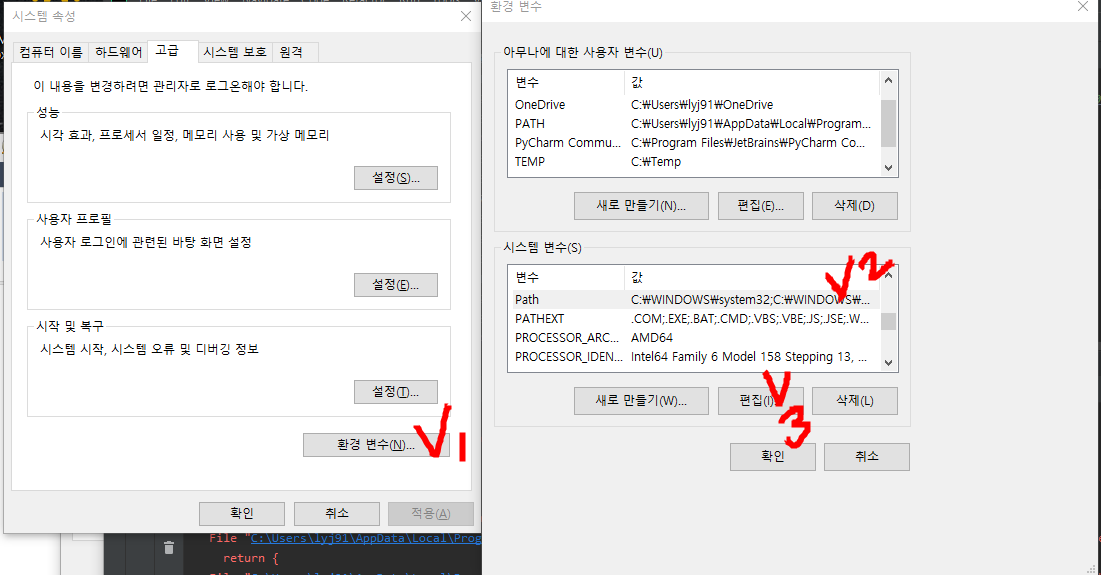
2-1. 단축키 Window + S 키를 누르고 환경 이라고 쓴다.

2-2. 환경변수 - path를 편집
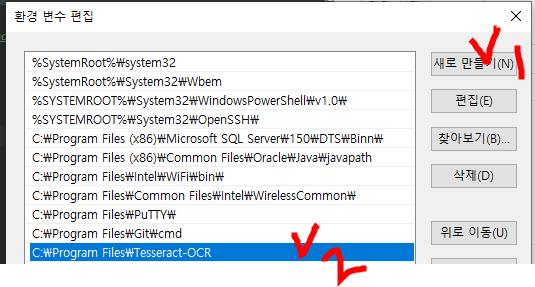
2-3. 프로그램 다운로드 위치인 C:\Program Files\Tesseract-ORC 를 등록한다. (필자는 62비트)
32비트인 사람들은 C:\Program Files (x86)\Tesseract-ORC 에 있을 것이다.
2-4. cmd로 tesseract 라고 치면 아래와 같이 나와야 설치 및 설정이 된것이다.

3. 필요한 라이브러리 패키지 설치
해당 코드를 사용하기 위해서는 아래 라이브러리가 필요하다.
필자는 opencv만 있으므로 나머지 2개를 추가로 설치했다.
- 패키지 설치
pip install pillow
pip install pytesseract
pip install opencv-python
pip install pillow
pip install pytesseract
pip install opencv-python

파이썬 코드
'''
reference link : https://junyoung-jamong.github.io/computer/vision,/ocr/2019/01/30/Python%EC%97%90%EC%84%9C-Tesseract%EB%A5%BC-%EC%9D%B4%EC%9A%A9%ED%95%B4-OCR-%EC%88%98%ED%96%89%ED%95%98%EA%B8%B0.html
Have to download OCR program firstly.
Link : https://github.com/UB-Mannheim/tesseract/wiki
environment : Window 10, python 3.6
tesseract ver : v5.0.0.20190526.exe
- 이미지 글자 추출 테스트
cmd > tesseract path\name.png stdout
- 패키지 설치
pip install pillow
pip install pytesseract
pip install opencv-python
'''
import cv2
import os
try:
from PIL import Image
except ImportError:
import Image
import pytesseract
# 설치한 tesseract 프로그램 경로 (64비트)
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract'
# 32비트인 경우 => r'C:\Program Files (x86)\Tesseract-OCR\tesseract'
# 이미지 불러오기, Gray 프로세싱
image = cv2.imread("digit.png")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# write the grayscale image to disk as a temporary file so we can
# 글자 프로세싱을 위해 Gray 이미지 임시파일 형태로 저장.
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray)
# Simple image to string
text = pytesseract.image_to_string(Image.open(filename), lang=None)
os.remove(filename)
print(text)
cv2.imshow("Image", image)
cv2.waitKey(0)위 코드는 이미지파일에서 글자(숫자, 영어)를 추출해서 text로 출력한다.
(테스트 1 - 숫자 출력 ) digit.png 파일


(테스트 2 - 영어와 숫자 출력 ) eng_digit.png 파일


(테스트 3 - 긴 영어문장 출력 ) sentences.png 파일


(테스트 4 - 코드에 한글 옵션을 추가해서 한글도 출력해본다.)
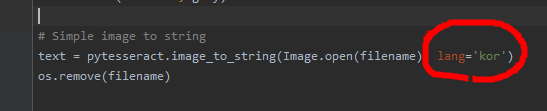


글자가 명확할 수록 더 잘 인식이 된다.
여러가지 테스트를 해보길 바란다.
<영상처리 관련 독특한 직업 스마트시티CCTV 관제사 자격증>
https://ansan-survivor.tistory.com/921
독특한 자격증, 스마트시티 CCTV 관제사 자격증! (스마트시티 자격증, 4차산업 자격증)
4차산업 혁명과 AI 빅데이터가 발전하고 있는 요즘에는 다양한 독특한 자격증들이 생겼다. 이중 아주 특이한 CCTV관제사 자격증이란 것이 있다. 큰 장점은 다양한 업종에서 종사할 수 있다. 요즘
ansan-survivor.tistory.com
'파이썬(python) > Python OpenCV' 카테고리의 다른 글
| [Python OpenCV] 왜곡된 이미지 펼치기, 굽어진 이미지 펼치기, 이미지 보정 (0) | 2020.09.17 |
|---|---|
| [Python OpenCV] 선분을 파악하고 선분의 중심에 수직선을 긋기 (0) | 2020.09.17 |
| [Python OpenCV] 이미지 대조 색상 강조 시키기, 이미지 Contrast 기법 (0) | 2020.09.17 |
| [Python OpenCV] 두개의 이미지를 하나로 합치기 (0) | 2020.09.17 |
| [Python OpenCV] 파이썬 바코드(barcode), QR코드 인식 프로그램 코드 (0) | 2020.09.17 |